
How Microsoft Power Platform is helping to modernize and enable...
In this webinar, our experts showcase a variety of demo use cases of how different components of the...
A successful Microsoft Dynamics CRM implementation hinges on good data and being able to reference data easily and accurately. Scribe is an excellent tool that can help manage that data and the appropriate references to it. Today, we will examine using Cross Reference Keys in Scribe Insight to ensure that your source and target data can reference one another with both simplicity and accuracy.
Cross Reference Keys in Scribe Insight provide a way to maintain a mapping of values between the primary key (GUIDs, in Dynamics CRM) values between two sets of data. This allow us data-oriented folks to have a clear understanding of what rows in a source import/migration correspond to what rows in a target.
The requirement we will be using Cross Reference Keys for today is to maintain a list of CRM GUIDs for a migration of many thousands of rows in a text (CSV) file to CRM. We want to ensure that we have the CRM GUID for each record we create from each row in the text file. This is especially helpful if the data being migrated has no inherent primary key (think about a generic list of contacts in an Excel spreadsheet) but we want to be able to reference specific rows in the source dataset in the future. This could be for continuation of the migration after failures, or for being able to validate data on a detailed level, among other things.
For this purpose, we will use Cross Reference Keys to write the CRM GUID to a SQL database, with each row GUID corresponding to a custom temporary primary key created using contact first name, last name, and email. Then, once we have the GUID recorded, we no longer need this makeshift primary key concatenation.
To begin, in your Scribe Workbench, click the key icon in the top menu bar. This will open the Cross Reference Keys window.
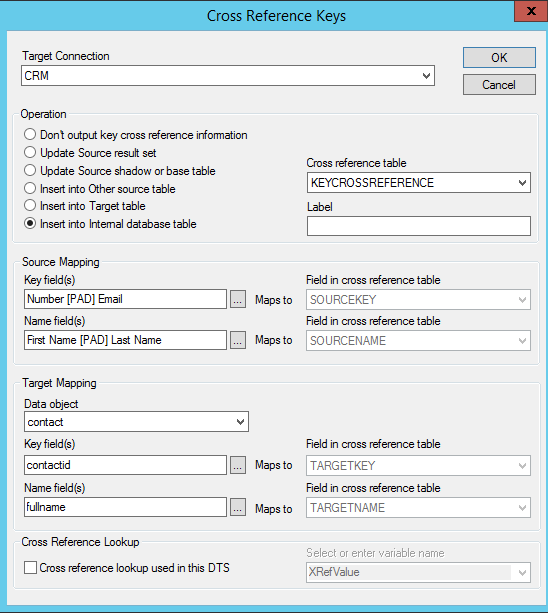
In this window, you can select the target connection you wish to cross reference with your source data, and the operation you want to occur for the cross referencing. For our purposes, we will write the data to the SCRIBEINTERNAL SQL database. This is done by selecting the operation 'Insert into Internal database table'. The option to choose the table to write to is also available, however, we will use the default KEYCROSSREFERENCE table.
Next, source and target key fields need to be specified. Since we are cross referencing two datasets using primary keys for each, we must specify the primary key for each dataset (source and target). We also must specify a name to go with those primary keys to allow for a more human-understandable reference outside of the primary key string.
Now, when the package is run, data will flow to the target CRM as intended, however, there will also be primary key values being written to the SCRIBEINTERNAL database table specified after the CRM insert is complete. In this way, a full list of corresponding GUIDs will be recorded for each CSV row inserted into CRM.
Remember to check out other blogs on Scribe and Dynamics CRM!
Best of luck in your future data migration/integration adventures, and remember to contact the friendly data experts at PowerObjects should you need assistance!






